Amazon Bedrock Part 3: Amazon Neptune Graph database Q&A LangChain Agent with Amazon Bedrock and Anthropic Claude
Disclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
This article is the 3rd part of my Amazon Bedrock series.
Here are the links for the previous articles :
Amazon Bedrock Part 1 : RAG with Pinecone Vector Store, Anthropic Claude LLM and LangChain — Income Tax FAQ Q&A bot
Amazon Bedrock Part 2: Hindi Text Summarization using Amazon Bedrock and Anthropic Claude
I have already posted about text-to-SQL capabilities of LLMs in conjunction with LangChain here. In this post, I want to take it up a notch and explore how does the LangChain Q&A chains work with Amazon Neptune Graph databases. How accurate Cypher queries can be generated by an LLM ?
For a quick prototype, I keep the use case simple :
- Create an Amazon Neptune Serverless cluster
- Create a Graph notebook on Amazon Neptune
- Load the famous MOVIE database using a .cypher file
- Create a LangChain Neptune OpenCypher QA chain
- Run the chain with Anthropic Claude-v2 and Amazon Bedrock
Create an Amazon Neptune Serverless Graph database cluster
In AWS console search for Amazon Neptune and land on the Neptune home page. We will create a Serverless Neptune cluster with a READ and WRITE endpoint and query using OpenCypher.

Then click on Databases and Create Database
Choose Serverless variant of Neptune Graph database and select the version 1.2.1.0.R6

Provide a db-cluster identifier and I selected 2–20 as the minimum and maximum NCU(Neptune Capacity Units), where 1 NCU = 2 GiB (gibibyte) of memory (RAM) along with associated virtual processor capacity (vCPU) and networking and I select the Development template.

For my quick prototype I select a single Availability Zone(AZ) deployment and deploy in my default vpc

To easily query my Neptune Graph database I create a notebook instance as well.
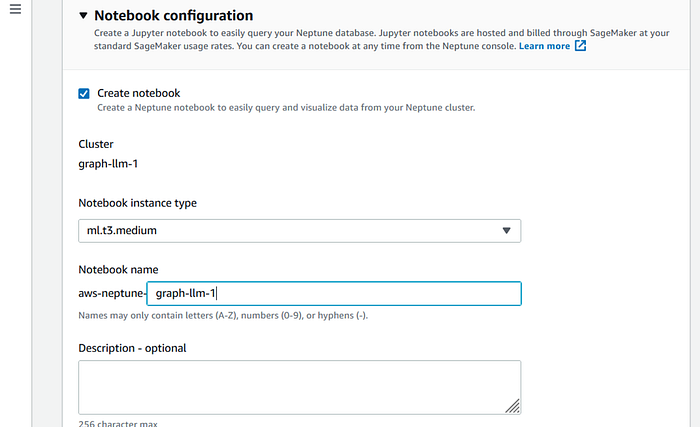
I also create a brand new IAM role for the Graph notebook to access SagaMaker, S3 etc ..
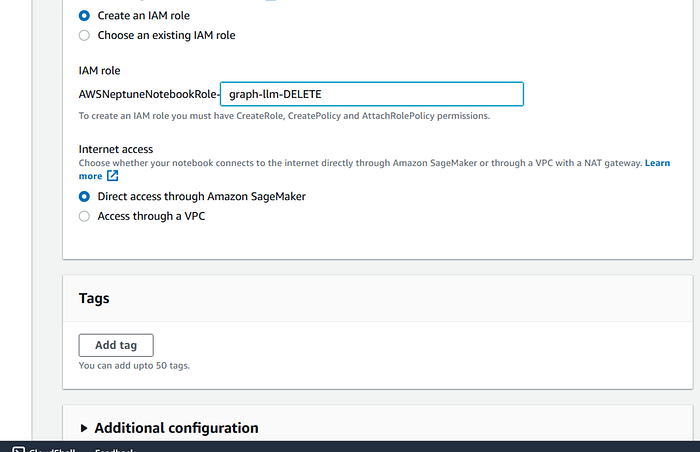
Click on Create Database to start provisioning the Neptune cluster.
Took ~6–8 minutes to get my Neptune Graph DB cluster up and running.
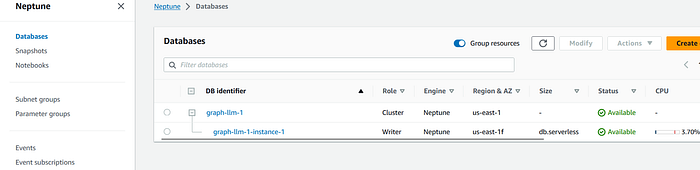
Create a Graph notebook on Amazon Neptune
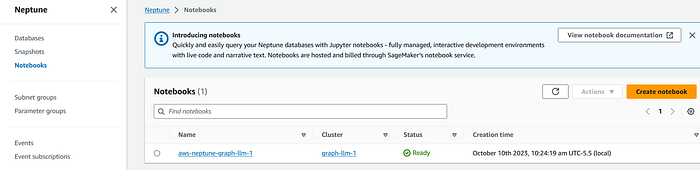
Once, you click the Notebooks link on the left navigation bar, you would also see that the Graph notebook is also provisioned :
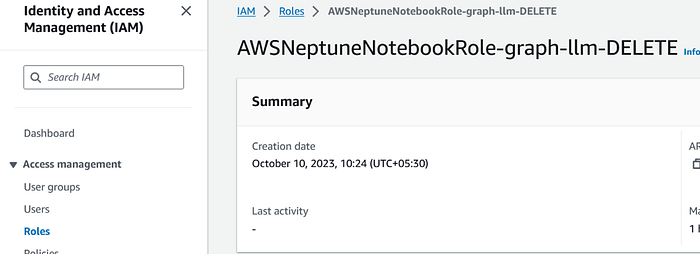
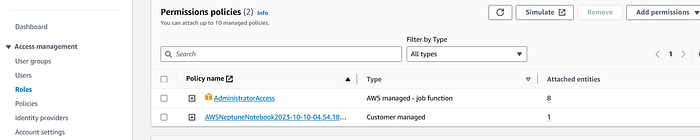
In order to run LangChain and Claude-v2 models using Amazon Bedrock, let’s provide the requisite privileges to the notebook role. Since, this is a quick prototype, I am taking a shortcut and adding administratoAccess , but, for PRODUCTION scenarios, please follow the principle of least privileges :
Then select the graph notebook and click on Open JupyterLab from the Actions menu :

With this, you land on the brand new JupyterLab launcher page :
You would also see the invaluable sample notebooks on the left hand side for querying Neptune and various ML and Data Science tasks.
For my quick experiment, I will launch a new notebook and start interacting with Neptune. Click File -> New -> Notebook and create a new notebook.

Once your new notebook is launched, select Python3 as the kernel.
Load the famous MOVIE database using a .cypher file
For running OpenCypher queries, Enptune notebooks provide the %%oc magic command. Let’s start with the status of the Neptune cluster :
%statusAnd I got the response from a healthy cluster :
{'status': 'healthy',
'startTime': 'Tue Oct 10 05:06:06 UTC 2023',
'dbEngineVersion': '1.2.1.0.R6',
'role': 'writer',
'dfeQueryEngine': 'viaQueryHint',
'gremlin': {'version': 'tinkerpop-3.6.2'},
'sparql': {'version': 'sparql-1.1'},
'opencypher': {'version': 'Neptune-9.0.20190305-1.0'},
'labMode': {'ObjectIndex': 'disabled',
'ReadWriteConflictDetection': 'enabled'},
'features': {'SlowQueryLogs': 'disabled',
'ResultCache': {'status': 'disabled'},
'IAMAuthentication': 'disabled',
'Streams': 'disabled',
'AuditLog': 'disabled'},
'settings': {'clusterQueryTimeoutInMs': '120000',
'SlowQueryLogsThreshold': '5000'},
'serverlessConfiguration': {'minCapacity': '2.0', 'maxCapacity': '20.0'}}Notice, how the serverlessConfiguration parameter denotes the auto-scaling limit.
Next, install boto3, botocore and langchain dependencies to call the LLM (Claude-v2) :
%pip install --upgrade --quiet boto3 botocore langchainNext, connect with our Neptune graph database using the reader endpoint, by clicking on the Neptune cluster name and selecting the reader endpoint :
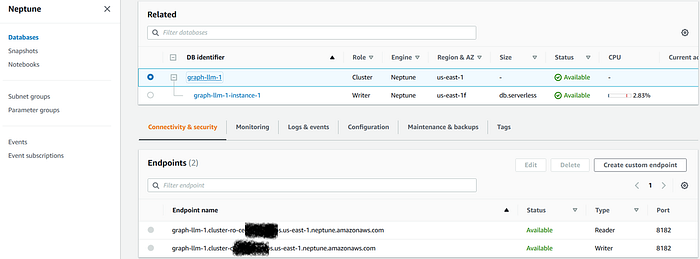
Once, we have the Neptune reader endpoint, let’s create a connection variable :
from langchain.graphs import NeptuneGraph
host = "graph-llm-1.cluster-ro-************.us-east-1.neptune.amazonaws.com"
port = 8182
use_https = True
graph = NeptuneGraph(host = host, port = port, use_https=use_https)Next, copy the text from the .cypher file, here.
This creates the famous MOVIE graph database using the popular OpenCypher syntax. To run it, use the %%oc magic command in the notebook cell and paste the content of the file underneath it, something like this :
%%oc
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
.
.
.
.
<Rest of the content from the cypher file attached>
This will create the MOVIE graph. You should get a success response like below :
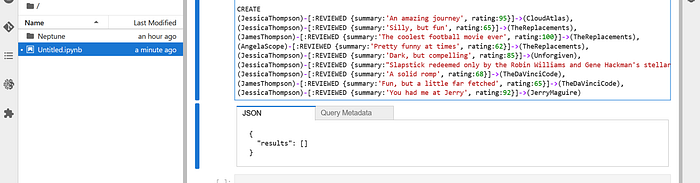
In case, you are interested, this is a partial graph view of the MOVIE database :
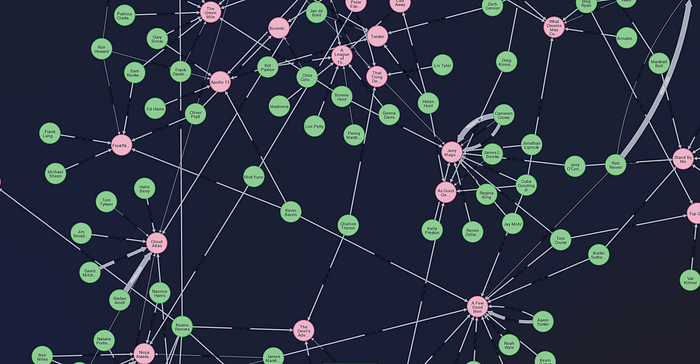
We can test if we got the nodes and the relationships alright with the following OpenCypher query :
%%oc
WITH TomH
MATCH (TomH)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d) RETURN m,d LIMIT 10;And it should work and give you the information and relationships for Tom Hanks.
I started learning the syntax of OpenCypher queries with the MOVIE graph database, and I have a soft corner for this database ! There are other examples as well, like Northwind graph database for a retail store which you might find interesting as well.
I am done with the first 3 tasks :
- created an Amazon Neptune Graph database cluster
- created a graph jupyterlab notebook
- created and populated a graph MOVIE database
Create a LangChain Neptune OpenCypher QA chain with Amazon Bedrock
Now, let’s create a LLM reference with Amazon Bedrock. I choose Claude-v2 as the LLM to run the NeptuneOpenCypherQAChain and ask questions on the Graph database and let’s test if it can generate the right OepnCypher queries under the hood and provide the best answer :
from langchain.llms.bedrock import Bedrock
from langchain.chains import NeptuneOpenCypherQAChain
modelId = 'anthropic.claude-v2'
model_kwargs = {
"max_tokens_to_sample": 512,
"temperature": 0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["\n\nHuman:"]
}
llm = Bedrock(
model_id=modelId,
model_kwargs=model_kwargs
)Run the chain with Anthropic Claude-v2 and Amazon Bedrock
Now, that my LLM Claude is configured to run with Amazon Bedrock, let’s start the question-answer chain :
chain = NeptuneOpenCypherQAChain.from_llm(llm = llm, graph=graph,verbose=True,)
chain.run("who played in Top Gun ?")And, here’s the fascinating response from Anthropic Claude-v2 :
> Entering new NeptuneOpenCypherQAChain chain...
Generated Cypher:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie {title:'Top Gun'})
RETURN p.name
Full Context:
{'ResponseMetadata': {'HTTPStatusCode': 200, 'HTTPHeaders': {'transfer-encoding': 'chunked', 'content-type': 'application/json;charset=UTF-8'}, 'RetryAttempts': 0}, 'results': [{'p.name': 'Tom Cruise'}, {'p.name': 'Kelly McGillis'}, {'p.name': 'Val Kilmer'}, {'p.name': 'Anthony Edwards'}, {'p.name': 'Tom Skerritt'}, {'p.name': 'Meg Ryan'}]}
> Finished chain.
' Based on the provided information, the main actors in Top Gun were Tom Cruise, Kelly McGillis, Val Kilmer, Anthony Edwards, Tom Skerritt, and Meg Ryan.'Bedrock works as the orchestrator to route the query to NeptuneOpenCypherQAChain from LangChain, and then Claude-v2 generates the OpenCypher query to perfection and returns the response in natural language(English, in this case !).
Great to see how the QA chain generates the OpenCypher query, executes it and returns the answer in natural language !
You can copy the OpenCypher query from the response and run it again on a new cell :
%%oc
MATCH (p:Person)-[:ACTED_IN]->(m:Movie {title:'Top Gun'})
RETURN p.nameAnd get the same response, albeit, not in a natural language form :-)
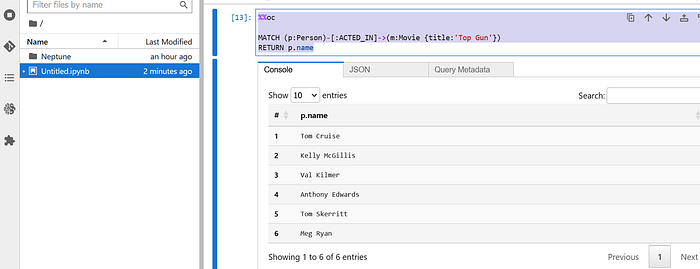
With Bedrock, LangChain and Neptune, we can build powerful Graph database applications with converational interfaces for manufacturing, CPG, healthcare verticals and the possibilities are endless !
Notebook attached here.
Happy Coding !
